
elasticsearch에 대해서 처음 접하게 됐을때 다들 기본적으로 검색을 할때 사용되는 도구다라고만 할수 있는데 준 실시간성으로 로그시스템을 구축할때 elasticsearch와 함께 logstash, kibana 그리고 요즘엔 filebeat까지 합쳐 elk 스택이라 불리며 자주사용되는 스택이 있습니다.
1. 기본 개념
각각의 구성 요소들이 담당하는 큰 역할에 대해 알아볼 필요가 있습니다.
- Elasticsearch
- 로그데이터를 저장하고 검색하는 역할을 담당
- 실시간 분석과 검색을 지원하며, 데이터베이스 쿼리와는 다르게 RESTFul API를 통해 데이터에 액세스 할 수 있음
- Logstash
- 로그 데이터 수집 및 필터링, 변환 ,파싱하는 역할을 담당
- 실질적으로 로그에 출력되길 원하는 내용만을 필터링하는 역할
- pipeline을 통해 여러개의 로그데이터 별로 설정을 진행할 수 있음
input, filter ouput으로 이루어져 있으며 input, output, filtering에 많은 플러그인들을 제공하고 있어 손쉽게 사용 가능합니다.
아래의 주소에서 사용가능한 plugin과 사용방법이 자세히 나와 있으니 참고 해주시기 바랍니다.
Input plugins | Logstash Reference [8.9] | Elastic
www.elastic.co
- Kibana
- ElasticSearch 데이터를 시각화하는 도구로, 로그데이터를 분석하고 대시보드화 하는 역할을 담당
- 뿐만 아니라 elasticsearch의 모든 설정을 손쉽게 관리 할 수 있도록 GUI 역할또한 담당
- Kibana는 다양한 시각화 도구를 제공하며, 기본적으로 로깅용 뿐만 아니라 시간대별, 지리적, 통계 등 다양한 방식으로 데이터를 시각화 할 수 있음.
kibana 또한 Elasticsearch 뿐만아니라 여러 plugin 형태로 제공된 저장소를 손쉽게 연결 및 관리 하여 시각화 할 수 있는 아주 강력한 도구입니다.
- Filebeat
- 데이터 추출 및 전송을 담당
- 경량화된 로그 수집 도구 역할
- resource(CPU와 RAM)를 상당히 적게 소모함
- 간단한 filter기능도 제공하지만 이는 logstash로 대체해 사용
사실, Filebeat가 왜 필요한가? 라는점에 초점을 맞춰 봐야합니다.
기존에 logstash가 담당하는 로그 수집 역할만을 filebeat가 담당하고 있습니다. 왜 logstash에서 기능을 제거했을까? 이유는 바로 jvm 위에서 동작하는 logstash의 리소스 부담을 줄이기 위해서 입니다.
filebeat와 logstash의 베이스는 언어자체에서도 큰 차이가 있습니다. filebeat=Go, logstash=java 베이스 코드로 짜여져 있으며 filebeat의 컨셉은 경량화된 로그 수집기 입니다. 기본적으로 로그 수집 자체의 역할만을 담당하여 서버의 CPU와 RAM을 상당히 적게 소모하여 logstash나 아에 elasticsearch로 전송할 수 있습니다.
그렇다면 어떻게 서버 구성을 하는게 이점이 될수 있을까? 생각해봅시다.
2. 인프라 구성
Filebeat는 서버의 자원을 최소화하여 로그 수집할 수 있는 장점이 있습니다. 하지만, 아래와 같이 구성할경우, 어떨까요?
3대의 ec2 인스턴스가 각각 존재하고 하나의 서버안에 elk + filebeat 스택을 구성했다고 가정해 봅시다.
물론 elk 인스턴스의 물리적 리소스가 굉장히 큰 서버라면 문제없이 동작할것입니다. 하지만, filebeat가 나온 히스토리를 생각해봅시다.
기존의 logstash의 작업중 로그 수집의 리소스를 분리해 물리적인 리소스를 적게 소모하는 경량화된 로그수집기입니다. 과연 filebeat가 필요할까요? 라는 생각이 듭니다.
만약 위와같은 구조로 구성한다면, filebeat를 제외한 logstash에게 로그 수집의 역할까지 담당하게 하는것이 좋은 패턴이 될것입니다.
그렇다면 어떻게 구성하는게 좋을까요?
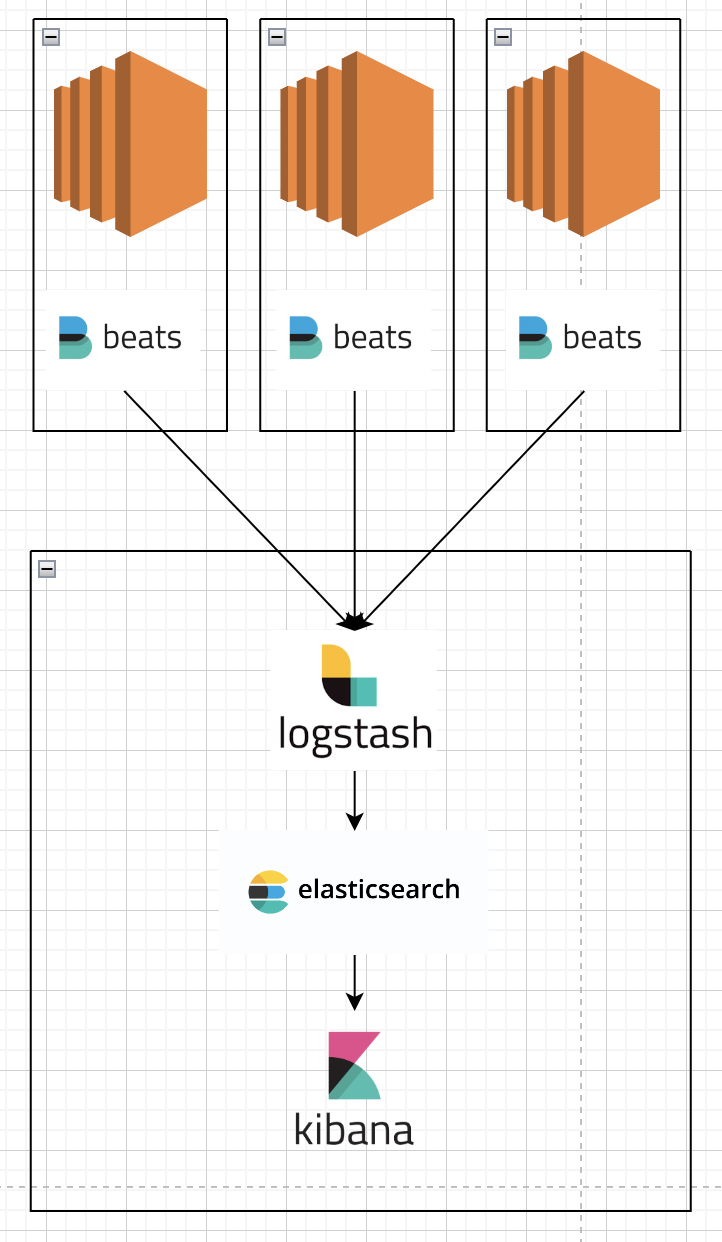
위와 같은 패턴으로 ec2 인스턴스 각각에 filebeat를 설치하여 로그를 수집한뒤 logstash가 있는 5044포트로 로그를 전송하는 역할만 담당하게 구성하면됩니다. 서버의 자원에 따라 elasticsearch와 kibana를 분리하는것도 방법이 될수 있으나 filebeat를 어디에 배치하느냐가 elk와 filebeat의 공존의 이유를 가장 잘 설명한 방법이 될수 있습니다.
logstash를 여러대 띄어서 관리하는 방법도 있지 않을까?하는 생각도 들수 있지만 logstash의 경우, pipeline형태로 여러대의 logstash 자원을 관리할 수 있어 이기능을 적극적으로 활용하여 관리해주시기 바랍니다.
3. elk 설치 튜토리얼
mac을 기준으로 elk 스택 설치 방법에 대해 설명드리겠습니다.
일단 elasticsearch, kibana, logstash, filebeat를 brew 명령어를 통해 설치해주시기 바랍니다.
brew install filebeat-full
brew install logstash-full
brew install elasticsearch-full
brew install kibana-full설치가 완료 되었다면, 기본적으로 filebeat의 output은 localhost:5044, logstash의 output은 localhost:9200, kibana의 input은 localhost:9200으로 구성되어 있습니다.
- filebeat
/usr/local/etc/filebeat 위치의 filebeat.yml
filebeat.inputs:
- type: log
id: test-filestream
enabled: true
paths:
- /usr/local/var/log/sample.log
# exclude_lines: ['^DBG']
# include_lines: ['^ERR', '^WARN']
# multiline.pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2}[[:space:]]
# multiline.negate: true
# multiline.match: after
output.logstash:
hosts: ["localhost:5044"]filebeat의 설정은 위와같이 기본적으로 로그를 수집할 input과 output으로 나뉘어져있습니다.
Filebeat Reference [8.9] | Elastic
www.elastic.co
input과 output에 본인이 원하는 플러그인 형태로모두 명시해서 사용하시면 되며 위의 자습서에서 확인 후 요구사항에 따라 변경해주시길 바랍니다.
위 설정의 경우, /usr/local/var/log/sample.log 이경로의 로그 파일을 input대상으로 확인하며 output으로 localhost:5044의 로그스태시로 보낸다는 간단한 설정입니다.
최근 트러블 슈팅간 syslog에서 error로그를 수집하기 위해 설정을 진행했는데 실질적으로 필요한 traceback로그는 수집이 안되고 500에러만 출력되는 문제가 생겨 이걸 하나의 라인으로 포함시켜 보내기 위해 multiline의 개념을 도입해 사용했습니다.
multiline은 기본적으로 정규표현식으로 패턴을 정의할 수 있으며, 특정 정규표현식의 패턴과 일치하지 않을경우 일치하지 않는 모든 로그를 한줄의 로그로 인식해 보낸다는 개념입니다. 여기엔 negate와, match로 설정을 진행해주셔야하며 설정 내용은 아래와 같습니다.
negate: 패턴이 무효화되는지 여부 정의, 기본값은 false
match: 일치하는 라인을 하나로 볼지 일치하지 않는 라인을 하나로 볼지 결정
| negate | match | 결과 |
| false | after | 패턴과 일치하는 연속줄을 일치하지 않는 이전줄에 포함 |
| false | before | 패턴과 일치하는 연속 줄은 일치하지 않는 다음줄 앞에 포함 |
| true | after | 패턴과 일치하지 않는 연속줄을 일치하는 이전 줄에 추가 |
| true | before | 패턴과 일치하지 않는 연속 줄은 일치하는 다음줄 앞에 추가 |
syslog의 특성상 시스템의 모든로그가 출력되기 때문에 수집될 대상의 로그의 경우수가 너무나 많기 때문에 exclude_lines와 include_lines를 적절히 설정하여 수집되는 로그의 기준을 확실히 정하는것이 작업의 리소스를 줄일 수 있는 방식이 될것 입니다.
- logstash
여러 logstash 설정 방식이 존재하겠지만 pipeline형식으로 관리하는 방식으로 리뷰하겠습니다.
/usr/local/etc/logstash 위치에 conf.d라는 디렉터리를 생성 후 sample.cfg 파일을 생성해줍니다.
input {
beats {
port => 5044
}
}
filter {
if "target log" in [message] {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:log_datetime} %{LOGLEVEL:level} %{DATA:log_message}: %{GREEDYDATA:json_data} %{SPACE}\[PID:%{NUMBER:pid}:%{DATA:thread}\]" }
}
date {
match => [ "log_datetime", "yyyy-MM-dd HH:mm:ss,SSS" ]
timezone => "Asia/Seoul"
}
}
else {
drop { }
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}input
Logstash가 Beats 입력 플러그인을 통해 로그 데이터를 수신한다는 것을 정의합니다. 이 설정에서는 5044 포트를 통해 Beats로부터 들어오는 데이터를 수신하도록 설정되어 있습니다.
filter
데이터 필터링 및 구문 분석을 수행하는 부분입니다. message 필드에 "target log"가 포함되어 있는 경우에만 실행됩니다.
- grok 필터는 로그 메시지를 정규 표현식을 사용하여 구문 분석하여 필드로 추출합니다. 예를 들어, %{TIMESTAMP_ISO8601:log_datetime}은 ISO 8601 형식의 타임스탬프를 log_datetime 필드로 추출합니다.
- date 필터는 log_datetime 필드의 값을 지정된 패턴에 맞춰서 파싱하여 날짜 및 시간 필드를 생성합니다. 지정된 타임존인 "Asia/Seoul"로 변환됩니다.
만약 "target log"가 message 필드에 없는 경우에는 drop 필터를 사용하여 이벤트를 삭제하므로 처리되지 않습니다.
output
필터링 및 구문 분석이 완료된 데이터를 Elasticsearch에 색인하는 부분입니다. elasticsearch 출력 플러그인을 사용하여 데이터를 Elasticsearch 클러스터로 전송합니다. hosts에는 Elasticsearch 클러스터의 호스트 주소를 설정하며, index는 색인 이름을 설정합니다. 여기서는 "test-" 다음에 날짜를 추가하여 일별로 색인을 생성하도록 설정되어 있습니다.
기본설정을 정의했다면 /usr/local/etc/logstash/pipeline.yml 파일에 pipeline을 정의해줍니다.
- pipeline.id: beats-pipeline
pipeline.workers: 1
pipeline.batch.size: 1
path.config: "/usr/local/etc/logstash/conf.d/sample.cfg"logstash의 동작을 위한 관련한 모든 기본 설정은 마무리가 되었습니다.
elasticsearch와 kibana의 경우, 기본적으로 logstash의 5044를 인풋으로 그리고 9200포트를 기본 elasticsearch로 바라보고 있기 때문에 단순히 실행만 해주신다면 문제없이 기본적인 로깅 시스템 세팅이 마무리됩니다.
brew services start filebeat-full
brew services start logstash-full
brew services start elasticsearch-full
brew services start kibana-full이번 챕터에서 다뤄본 내용은 elk+beat 스택의 동작을 위한 기본 설정만 다뤄봤기 때문에 실제로 어떤 데이터를 수집할것인지에 따라 beat와 logstash의 설정은 달라질수 있으며 실제로 데이터 수집이후 elasticsearch의 lifecycle이나 index pattern등 정의할것들에 대한 작업들은 많이 남아 있습니다. 기본적으로 비즈니스 요구사항을 먼저 파악한 후 이러한 설정들을 어떻게 설정할지는 공식문서를 통해 더욱 구체화 해주시길 바랍니다.
이후에 다뤄볼 내용은 indextemplate과 cluster 관리에 대해 더욱 자세히 알아보도록 하겠습니다.
감사합니다.
'기술 > 데이터 엔지니어링' 카테고리의 다른 글
| Iceberg vs Hudi vs Delta Lake, 뭘 써야 할까요? (1) | 2025.01.30 |
|---|---|
| Parquet를 통해 효율적으로 데이터 관리하기 (0) | 2024.05.06 |
| 데이터 엔지니어링(1) - elasticsearch 너 누구야? (0) | 2023.08.20 |
| 데이터 엔지니어링(0) - 데이터 엔지니어링이란 무엇인가? (0) | 2023.08.09 |