데이터 엔지니어링이란 무엇이고 각 단계별 어떤기술이 사용되는지 그리고 데이터 엔지니어링에서 사용되는 용어에 대해 먼저 알아보려 합니다.
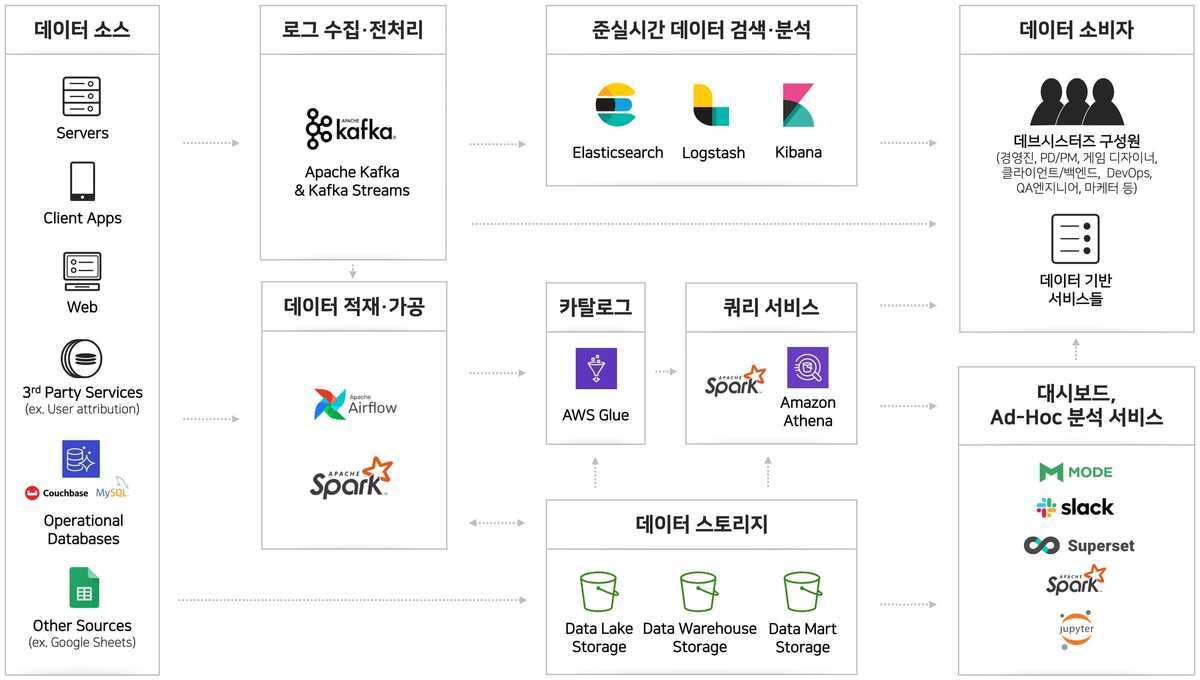
위의 이미지를 보다시피 데이터 엔지니어링의 목적은 여러 데이터 소스들에서 유의미한 데이터들을 수집, 가공 및 분석하여 데이터 소비자들에게 알맞게 전달하는 것이 목적입니다.
단계별로 아래의 과정을 거쳐 소비자들에게 전달됩니다.
1. 데이터 소스
데이터 엔지니어링의 첫 번째 단계는 데이터 소스를 식별하고 확보하는 것입니다. 데이터는 다양한 소스에서 나올 수 있습니다. 내부 시스템 로그, 외부 API, 데이터베이스, 외부 웹사이트 등이 데이터 소스의 예시입니다. 데이터를 수집할 때 어떤 유형의 데이터를 어떻게 수집할 것인지 결정하는 것이 중요합니다.
ex) 비/관계형 데이터베이스, excel, log, etc..
2. 로그 수집, 전처리
데이터를 소스로부터 수집하면 다음 단계는 데이터를 로그로 기록하고 필요한 형식으로 전처리하는 것입니다. 로그 수집은 데이터의 추적 가능성과 안정성을 보장하는 데 도움이 됩니다. 데이터 전처리는 데이터를 클린하게 만들어서 분석이나 저장 단계에서 문제가 발생하지 않도록 하는 과정입니다. 이 단계에서는 데이터 누락, 이상치, 중복 등을 처리하고 필요한 형식으로 변환합니다.
ex) airflow, spark, kafka, elk, aws kinesis etc..
3. 데이터 저장
전처리된 데이터는 영구적으로 저장되어야 합니다. 데이터베이스 시스템을 활용하여 구조화된 데이터를 저장하거나, 분산 스토리지 시스템을 사용하여 대용량 데이터를 저장할 수 있습니다. 데이터 저장소를 선택할 때는 데이터의 양과 형태, 접근 속도, 보안 요구 등을 고려해야 합니다. 일반적으로 데이터 엔지니어는 데이터 웨어하우스, NoSQL 데이터베이스, 분산 파일 시스템 등을 고려하게 됩니다.
ex) bigquery, s3, 비/관계형 데이터베이스, etc..
4. 데이터 시각화 (선택적)
데이터 시각화는 데이터를 이해하고 전달하기 위한 중요한 단계입니다. 데이터 시각화를 통해 데이터의 경향성, 패턴, 이상치 등을 빠르게 파악할 수 있습니다. 시각화 도구를 사용하여 그래프, 차트, 대시보드 등을 생성하여 데이터의 시각적 표현을 만들어냅니다. 데이터 시각화는 비즈니스 의사 결정이나 데이터 분석 결과를 공유할 때 매우 유용합니다. 실질적으로 이부분은 대부분 개발자분들 보다도 비개발직군분들이 다른 업무에서 의사결정에 활용하려는 목적으로 많이 사용됩니다.
ex) superset, tableau, kibana, slack, etc..
필자의 경우, 회사업무를 진행하며 경험해본 스택은 airflow, elk 스택, aws s3, kinesis, superset, bigquery, pandas 정도가 있습니다.
다음 챕터 부터는 elasticsearch 및 elk 스택, airflow, superset의 순으로 리뷰를 할예정이며 이후부터는 사용해보지 않은 apache spark, kafka에 대해 알아볼 예정입니다.
미리 각 기술이 사용되는 이유 및 요약을 하자면 아래와 같습니다.

1. airflow
위 사진이 airflow에 대해 가장 잘 설명된거라고 생각하는데 airflow는 쉽게 말해 데이터 엔지니어링 잡들을 통합적으로 관리해주는 스케줄링 도구라고 생각합니다. 기본적은 python기반의 코드로 작성되며 papermill이라는 라이브러리를 통해 jupyter파일을 주입할 수 있어 개인적으로 굉장히 큰 장점 중 하나라고 생각합니다.

2. elk스택 + filebeat
굉장히 유명한 오픈소스 검색엔진인 elasticsearch와더불어 함께 사용되는 logstash, kibana 그리고 최근들어 많이 함께 사용되는 filebeat를 통칭하는 것이 elk스택입니다. 거의 실시간으로 로그 및 데이터를 수집 및 시각화가 가능하여 많이 활용 됩니다. 각각의 역할에 대해 알아보면 아래와 같습니다.
- filebeat: 기존 로그 수집, 필터 및 전달까지 담당하던 logstash의 기능중 데이터 추출 및 전송의 역할을 담당하는 도구입니다. logstash도 충분한데 등장하게 된이유는 기본적으로 go로 작성된 filebeat의 경우 cpu와 ram과 같은 resource를 상당히 적게 소모하기 때문이며, 보통 경량화된 로그 수집 도구라고 알려져있습니다.
- logstash: 앞서 말한 바와 같이 로그 수집, 필터 및 전달을 담당하며 기본적으로 로그를 수집하는 input과 수집된 로그를 필터링하는 filter, 필터링된 데이터를 전달하는 output으로 구성되어 있으며 input과 output에 여러 플러그인을 제공하여 비교적 쉽게 사용 가능합니다.
- elasticsearch: 데이터 저장소 및 검색의 역할을 담당하며, 데이터베이스 쿼리와는 다르게 RESTFUL API를 통해 데이터에 액세스 할수 있습니다. 역색인을 통해 검색이 굉장히 빠릅니다.
- kibana: elasticsearch의 index 관리 및 데이터 시각화를 담당하고 있습니다.
3. superset
모든 과정을 거쳐 수집된 데이터들을 차트와 대시보드 단위로 쿼리해 소비자들에게 시각화하여 제공해주는 역할을 합니다. 개발자들도 볼수 있겠지만 대부분 비개발직군 분들이 유의미한 데이터를 통해 추후 업무에 활용할때 많이 사용됩니다.
4. kafka
Kafka는 대규모 실시간 데이터 스트리밍 아키텍처를 구성하는 데 사용되며, 웹 사이트의 로그 처리, 실시간 분석, 이벤트 소싱 등에 활용됩니다. ELK 스택과 함께 사용하여 로그 데이터를 Kafka로 수집하고, 이후 Logstash를 사용하여 데이터를 전처리하여 Elasticsearch로 전송하는 등 다양한 데이터 파이프라인을 구축할 수 있습니다.
5. spark
대규모 데이터 처리와 분석을 위한 오픈 소스 클러스터 컴퓨팅 프레임워크입니다. Hadoop의 MapReduce 모델을 보완하고, 빠르고 효율적인 데이터 처리를 제공하는 것이 주요 목표입니다.
chatGPT에게 데이터 엔지니어링에서 사용되는 토픽에 대해 리스트를 뽑아봤는데 아래와 같습니다.
- ETL (Extract, Transform, Load):
- Extract: 다양한 데이터 원본에서 데이터를 추출합니다.
- Transform: 추출한 데이터를 필요한 형식으로 변환하고 정제합니다.
- Load: 변환한 데이터를 타겟 데이터베이스나 데이터 웨어하우스에 로드합니다.
- Data Pipeline (데이터 파이프라인): 데이터의 이동과 변환 과정을 일련의 단계로 정의한 시스템 또는 프로세스입니다.
- Batch Processing (배치 처리): 대량의 데이터를 일괄적으로 처리하는 방식을 말합니다.
- Real-time Processing (실시간 처리): 데이터를 실시간으로 처리하고 분석하는 방식을 말합니다.
- Data Warehouse (데이터 웨어하우스): 다양한 데이터 원본에서 추출한 데이터를 통합하고 저장하는 중앙 저장소입니다.
- Data Lake (데이터 레이크): 다양한 유형과 형식의 데이터를 대규모로 저장하고 분석하기 위한 저장소입니다.
- Data Ingestion (데이터 인제스처): 외부 데이터 원본에서 데이터를 추출하고 처리 파이프라인으로 전송하는 과정을 말합니다.
- Data Transformation (데이터 변환): 데이터를 필요한 형식으로 변환하고 정제하는 작업을 말합니다.
- Data Modeling (데이터 모델링): 데이터의 구조와 관계를 정의하여 데이터를 효과적으로 저장하고 쿼리할 수 있도록 설계하는 작업을 말합니다.
- Schema (스키마): 데이터의 구조와 형식을 정의하는 설계도입니다.
- Data Governance (데이터 거버넌스): 데이터의 품질, 보안, 규정 준수 등을 관리하는 프로세스와 정책을 의미합니다.
- Data Quality (데이터 품질): 데이터의 정확성, 일관성, 완전성 등을 나타내는 개념입니다.
- Data Integration (데이터 통합): 여러 데이터 소스에서 데이터를 추출하고 통합하는 작업을 의미합니다.
- Data Partitioning (데이터 파티셔닝): 대량의 데이터를 논리적 또는 물리적으로 분할하여 관리하는 방식을 말합니다.
- Data Replication (데이터 복제): 데이터를 여러 위치에 복사하여 고가용성과 장애 복구를 보장하는 작업을 의미합니다.
- Data Catalog (데이터 카탈로그): 조직 내의 데이터 자산을 관리하고 검색할 수 있는 메타데이터 저장소를 말합니다.
회사에서 데이터 엔지니어링 업무를 주로 맡으며, 깊게 각각의 기술에 대해 알아볼 기회가 없었는데 이번기회를 통해 자세히 알아볼 예정입니다.
위에서 잠시 요약했던 기술에서 kafka는 aws kinesis firehose, spark는 pandas와 비교되지 않을까?하는 생각이 듭니다. 사실, 회사에서 kinesis firehose, pandas만으로도 업무 진행에 문제가 없어 필요성에 대해서는 확실히 파악하진 못했는데 추후 실습을 통해 리뷰하도록 하겠습니다.
감사합니다 :)
'기술 > 데이터 엔지니어링' 카테고리의 다른 글
| Iceberg vs Hudi vs Delta Lake, 뭘 써야 할까요? (1) | 2025.01.30 |
|---|---|
| Parquet를 통해 효율적으로 데이터 관리하기 (0) | 2024.05.06 |
| 데이터 엔지니어링(2) - elk 스택을 활용한 로깅시스템 구축하기 (0) | 2023.08.27 |
| 데이터 엔지니어링(1) - elasticsearch 너 누구야? (0) | 2023.08.20 |